
Predikce v energetice 5: Vhodný predikční nástroj
Předchozí díly seriálu objasnily, co vše lze predikovat a proč je to důležité, jaké predikční metody jsou v oblasti energetiky využívány a co se dá považovat za dobrý predikční model. Poslední článek této série odpoví na otázku, jak by měla vypadat predikce v praxi a co konkrétně má umět software určený k predikcím.
V předchozích dílech série bylo řečeno mnohé o tom, že spolehlivá predikce musí být založena zejména na správném predikčním modelu. Většina dodavatelů nástrojů určených pro predikce se tak i proto předhání v dosahování lepší přesnosti svých výpočtů a ladí své algoritmy k vysněné dokonalosti. Z praktických zkušeností ovšem vyplývá, že velkou slabinou firem využívajících predikční software je nastavení spolupráce okolních systémů, datových zdrojů a uživatelů s vlastním predikčním softwarem.
Existuje tak celá řada úloh a úkonů souvisejících s nejbližším okolím predikčního nástroje, kterým není věnována dostatečná pozornost, případně jsou prováděny manuálně, což zvyšuje riziko chyby. To má ve výsledku velice negativní dopad na výstupy, a tedy i na návazná obchodní rozhodnutí. Proto je dobré tyto úlohy, které budou v následujících odstavcích blíže popsány, podpořit vhodným systémem. Systematizace těchto aktivit prostřednictvím vhodného informačního systému či softwarového nástroje minimalizuje pravděpodobnost zanesení chyby způsobené lidským faktorem. Odměnou za tuto systematizaci je pak dosahování stabilních a velmi přesných výsledků predikce.
Stahování dat
Alfou a omegou jakékoliv predikce jsou kvalitní vstupní data. Problémem ovšem často bývá to, jak zajistit konzistenci, validitu a úplnost těchto dat. Vstupní data obvykle pocházejí z velkého množství zdrojů, bývají uchovávána v různorodých formátech a jsou dostupná v různých úrovních kvality. Kvalita dat je určena především tím, zda pocházejí z veřejně dostupných bezplatných zdrojů nebo se jedná o placený zdroj dat.
Vhodný nástroj by si měl poradit s automatickým stahováním dat z nejčastěji používaných zdrojů. Z těchto zdrojů lze jmenovat například Operátora trhu s elektřinou (OTE), provozovatele přenosových a distribučních soustav (ČEPS, ČEZ Distribuce, apod.), ČHMÚ nebo YR.NO jako příklady zdrojů meteorologických dat či energetické burzy (mj. PXE nebo EEX).
Ověřování dat
Poté, co jsou data automatický stažena, je nutné kontinuálně monitorovat jejich kvalitu. Na trhu je dnes velké množství nástrojů pro čištění dat, které se dají pro tuto úlohu dobře využít. V ideálním případě by však tuto úlohu měl plnit samotný predikční nástroj při každém získání nových dat z jakéhokoliv datového zdroje. Ověření či datové validace jsou pak realizovány prostřednictvím předem daných validačních postupů, které podle typu dat či zdrojů stanoví, co vše je potřeba kontrolovat a případně napravit.
Typicky se u dat na vstupu do predikčních modelů kontroluje úplnost, při které by mělo dojít k upozornění na případné chybějící úseky měření. Dále se ověřuje smysluplnost, kdy kontrola například upozorní například na situaci, že fotovoltaická elektrárna vyráběla v noci. Ověřuje se také konzistence dat, zda jsou záznamy v souladu s historickým vývojem. Ověřit tyto vlastnosti je nutné nejen u vstupních dat, ale i u dat na výstupu. Musí tedy dojít k ověření, že predikované hodnoty se pohybují v standardním předpokládaném rozpětí.
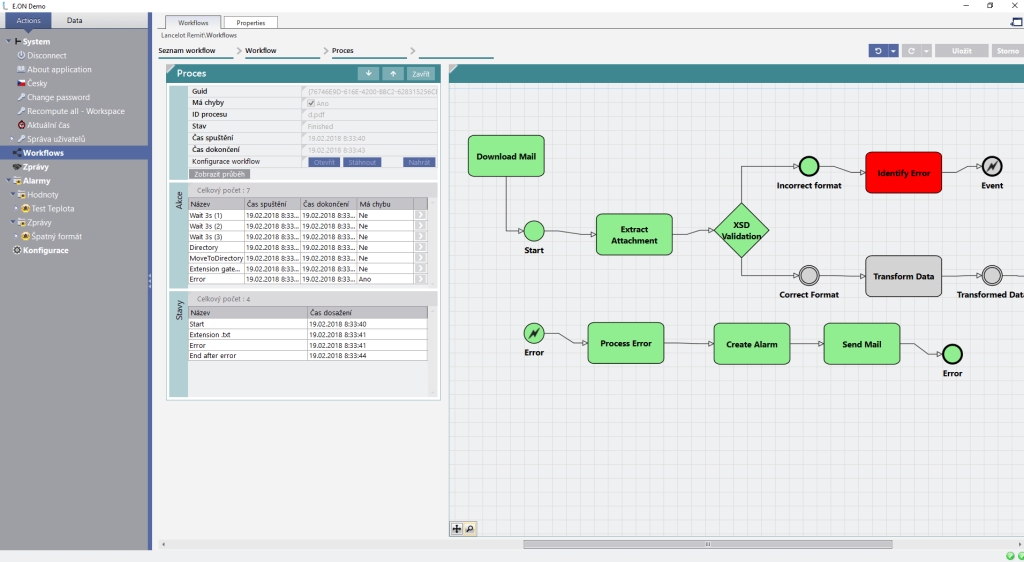
Notifikace
V návaznosti na ověřování datové kvality by měl nástroj umožňovat nastavení notifikací či alarmů, které uživatele upozorní na nestandardní či nežádoucí situace. Upozorňovat je možné také na případy, kdy jsou porušena některá kritéria datové kvality. Notifikace takovýchto událostí umožňují začít s řešením problémů dříve, než dojde k použití nevhodných dat, což by mělo za následek snížení přesnosti predikce. Notifikace mohou být doručovány jedním nebo vícero kanály, typicky emailem, SMS zprávou nebo pop-up oknem přímo v predikčním nástroji.
Stejně jako u ověřování dat jsou notifikace potřebné jak na vstupu, kdy nástroj kontroluje kvalitu vstupních dat, tak i na výstupu. Komplexní predikční nástroj by totiž měl být také schopen upozorňovat na situace, kdy například některá z predikovaných veličin překročí předem definovanou hodnotu.
Doplňování a oprava dat
Jakmile dojde k zachycení nežádoucí situace na úrovni vstupních dat, je nutné provést jejich úpravu. Systém může upozornit uživatele, že je potřeba manuálně upravit či doplnit data. Manuální doplnění bývá umožněno klasickým importem dat z Excelu, XML souboru aj. V určitých případech může systém provést nápravu či doplnění sám, když použije některou z dostupných metod.
Mezi často používané metody patří inteligentní interpolace. Například metoda Spline, vhodná pro aproximaci kratších úseků (jedná se o polynomickou funkci definovanou v intervalech), či metoda energetického posunu (automatické doplnění časové řady podle předchozího období s ohledem na víkendy a svátky). Tyto metody je pochopitelně nutné volit dle vhodnosti a případně je kombinovat.
Výpočet predikce
Samotnému modelu či predikčnímu algoritmu byl věnován samostatný článek série, v této části bude proto uvedeno, jak by mělo vypadat vhodné prostředí pro výpočty, tzv. výpočetní jádro. Výhodou dnešních pokročilých nástrojů je mj. možnost parametrizace výpočtů bez potřeby znalosti programovacích jazyků či pokročilé matematiky.
Dnes tak lze modely ladit prostřednictvím uživatelského rozhraní, aniž by se muselo zasahovat do zdrojového kódu. Nástroje používané v dnešní době umožňují pouze prostřednictvím myši poskládat složité vzorce o mnoha proměnných a ty okamžitě testovat (tzv. drag & drop). Vzhledem k tomu, že se typicky pracuje s velkými objemy dat, predikční nástroje by měly běžet na odpovídající infrastruktuře. Predikční nástroje by měly také poskytovat uživateli rychlou zpětnou vazbu v podobě okamžitých výpočtů a grafických vizualizací výstupů. Výpočetní jádro by si mělo také poradit se začleněním již naprogramovaných řešení v otevřených formátech, především v případech kdy např. existuje vhodný model napsaný v programovacím jazyku R či v Matlabu.
Výpočet samotný se dá rozdělit do dvou částí, první část se stará o poskládání predikované křivky a druhá o její vlastní predikci. Při skládání křivky je nutné započítat dynamiku portfolia, změny v jeho struktuře (příchozí a odchozí zákazníky). Pro dosažení vyšší přesnosti je dobré vhodně zkombinovat metodiky predikce shora a zdola. Vlastní algoritmy predikce pak kombinují matematické zákony (regrese, korelace), fyzikální zákony (saturace) se snahou vyjádřit lidské chování v predikčním algoritmu. Model jako celek pak může simulovat omezený ekosystém spotřeby a výroby elektrické energie.
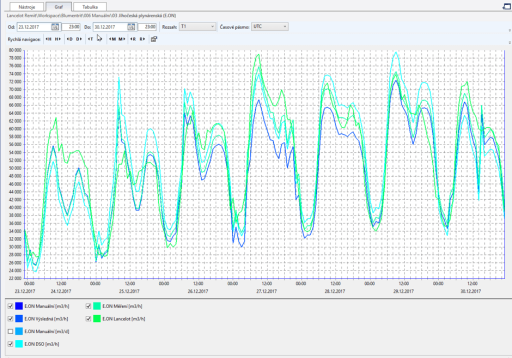
Reporting
Jakmile je k dispozici predikce vypočtená na základě relevantních dat, dochází k předávání výstupů v požadovaném formátu na potřebná místa a v daném čase. Takový report může obsahovat jednu predikci (křivku) a nebo zobrazovat jednotky až desítky výstupů, jejichž obsah je přizpůsoben potřebám konkrétních uživatelů. Zobrazení výstupů může být přizpůsobováno jak z pohledu reportovaných veličin (spotřeba, výroba, odchylka, směr odchylky, vývoj cen, …), tak z pohledu formátu (grafy, tabulky, interaktivní mapy, …).
Přestože je reporting běžnou součástí většiny dnešních softwarových nástrojů, je třeba myslet na to, aby byl reporting dostatečně flexibilní. Každý uživatel totiž může mít odlišné požadavky na zobrazované výstupy. V ideálním případě by měl umožňoval zobrazovat (nebo dokonce pouštět) výpočty/reporty z nástrojů, na které jsou uživatelé běžně zvyklí – nejčastěji MS Excel či jiné aplikace z rodiny MS Office.
Závěr
Ať už je pro podporu predikcí zvolen více či méně komplexní nástroj, vždy by měl splnit následující vlastnosti:
- měl by být použitelný (nekomplikovat lidem život, ale pomáhat jim),
- škálovatelný (zatímco dnes stačí jednoduchý nástroj, měl by růst s velikostí organizace),
- bezpečný (zejména dnes, kdy se ke všem aplikacím přistupuje vzdáleně z internetu)
- a hlavně funkční z pohledu účelu, kvůli kterému byl pořízen.
Pokud se nacházíte v situaci, kdy by vám mohl pomoci nástroj podobný tomu, který byl popsán v tomto článku, kontaktuje Ondřeje Synka (ondrej.synek@unicorn.com), autora tohoto dílu série, alternativně zanechte komentář níže.
Poděkování autora série
Za poskytnutí námětu, podkladů, cenných rad a informací bez, kterých by seriál nevznikl, a také za vstřícný přístup děkuji Ondřeji Synkovi a Martinovi Hrubému ze společnosti Unicorn Systems.



Komentáře v diskuzi mohou pouze přihlášení uživatelé. Pokud ještě účet nemáte, je možné si jej vytvořit na stránce registrace. Pokud již účet máte, přihlaste se do něj níže.
V uživatelské sekci pak můžete najít poslední vaše komentáře.
Přihlásit se